Preempt Pytorch Training Job
Arena supports Priority and Preempt the pytorch job, the following steps will show how to use this feature.
1. Create a yaml file to define a PriorityClass. There are two priorities defined here: critical and medium.
➜ cat priorityClass.yaml
apiVersion: scheduling.k8s.io/v1beta1
description: Used for the critical app
kind: PriorityClass
metadata:
name: critical
value: 1100000
---
apiVersion: scheduling.k8s.io/v1beta1
description: Used for the medium app
kind: PriorityClass
metadata:
name: medium
value: 1000000
submit the PriorityClass by kubectl.
➜ kubectl create -f priorityClass.yaml
priorityclass.scheduling.k8s.io/critical created
priorityclass.scheduling.k8s.io/medium created
2. Check the available resources.There are 3 nodes in total, and each node has 4 gpu cards.
➜ arena top node
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-huhehaote.172.16.0.205 172.16.0.205 master ready 0 0
cn-huhehaote.172.16.0.206 172.16.0.206 master ready 0 0
cn-huhehaote.172.16.0.207 172.16.0.207 master ready 0 0
cn-huhehaote.172.16.0.208 172.16.0.208 <none> ready 4 0
cn-huhehaote.172.16.0.209 172.16.0.209 <none> ready 4 0
cn-huhehaote.172.16.0.210 172.16.0.210 <none> ready 4 0
-----------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
0/12 (0%)
3. Submit a pytorch job with medium priority of 3 nodes and 4 cards, which occupies the full resources. In order to verify the effect, we can increase the epoch of training, extend the training time, and facilitate the experiment to view.
➜ arena --loglevel info submit pytorch \
--name=pytorch-priority-medium \
--gpus=4 \
--workers=3 \
--image=registry.cn-beijing.aliyuncs.com/ai-samples/pytorch-with-tensorboard:1.5.1-cuda10.1-cudnn7-runtime \
--sync-mode=git \
--sync-source=https://code.aliyun.com/370272561/mnist-pytorch.git \
--priority=medium \
"python /root/code/mnist-pytorch/mnist.py --backend gloo --epochs 200"
configmap/pytorch-priority-medium-pytorchjob created
configmap/pytorch-priority-medium-pytorchjob labeled
pytorchjob.kubeflow.org/pytorch-priority-medium created
INFO[0000] The Job pytorch-priority-medium has been submitted successfully
INFO[0000] You can run `arena get pytorch-priority-medium --type pytorchjob` to check the job status
4. Get the details of the this job. You can see that the task is running.
➜ arena get pytorch-priority-medium
STATUS: RUNNING
NAMESPACE: default
PRIORITY: medium
TRAINING DURATION: 3m
NAME STATUS TRAINER AGE INSTANCE NODE
pytorch-priority-medium RUNNING PYTORCHJOB 3m pytorch-priority-medium-master-0 172.16.0.208
pytorch-priority-medium RUNNING PYTORCHJOB 3m pytorch-priority-medium-worker-0 172.16.0.210
pytorch-priority-medium RUNNING PYTORCHJOB 3m pytorch-priority-medium-worker-1 172.16.0.209
5. Check the GPU card usage. It is all occupied.
➜ arena top node
NAME IPADDRESS ROLE STATUS GPU(Total) GPU(Allocated)
cn-huhehaote.172.16.0.205 172.16.0.205 master ready 0 0
cn-huhehaote.172.16.0.206 172.16.0.206 master ready 0 0
cn-huhehaote.172.16.0.207 172.16.0.207 master ready 0 0
cn-huhehaote.172.16.0.208 172.16.0.208 <none> ready 4 4
cn-huhehaote.172.16.0.209 172.16.0.209 <none> ready 4 4
cn-huhehaote.172.16.0.210 172.16.0.210 <none> ready 4 4
-----------------------------------------------------------------------------------------
Allocated/Total GPUs In Cluster:
12/12 (100%)
6. Submit a job with priority of critical to initiate preemption.
➜ arena --loglevel info submit pytorch \
--name=pytorch-priority-critical \
--gpus=1 \
--image=registry.cn-beijing.aliyuncs.com/ai-samples/pytorch-with-tensorboard:1.5.1-cuda10.1-cudnn7-runtime \
--sync-mode=git \
--sync-source=https://code.aliyun.com/370272561/mnist-pytorch.git \
--priority=critical \
"python /root/code/mnist-pytorch/mnist.py --backend gloo --epochs 50"
configmap/pytorch-priority-critical-pytorchjob created
configmap/pytorch-priority-critical-pytorchjob labeled
pytorchjob.kubeflow.org/pytorch-priority-critical created
INFO[0000] The Job pytorch-priority-critical has been submitted successfully
INFO[0000] You can run `arena get pytorch-priority-critical --type pytorchjob` to check the job status
7. Get the details of the this job.
➜ arena get pytorch-priority-critical
arena get pytorch-priority-critical
STATUS: RUNNING
NAMESPACE: default
PRIORITY: critical
TRAINING DURATION: 22s
NAME STATUS TRAINER AGE INSTANCE NODE
pytorch-priority-critical RUNNING PYTORCHJOB 22s pytorch-priority-critical-master-0 172.16.0.208
8. Check the job status of medium priority. It has become FAILED. One instance has been deleted due to preemption.
➜ arena get pytorch-priority-medium
STATUS: FAILED
NAMESPACE: default
PRIORITY: medium
TRAINING DURATION: 1m
NAME STATUS TRAINER AGE INSTANCE NODE
pytorch-priority-medium FAILED PYTORCHJOB 2m pytorch-priority-medium-master-0 172.16.0.210
pytorch-priority-medium FAILED PYTORCHJOB 2m pytorch-priority-medium-worker-0 172.16.0.209
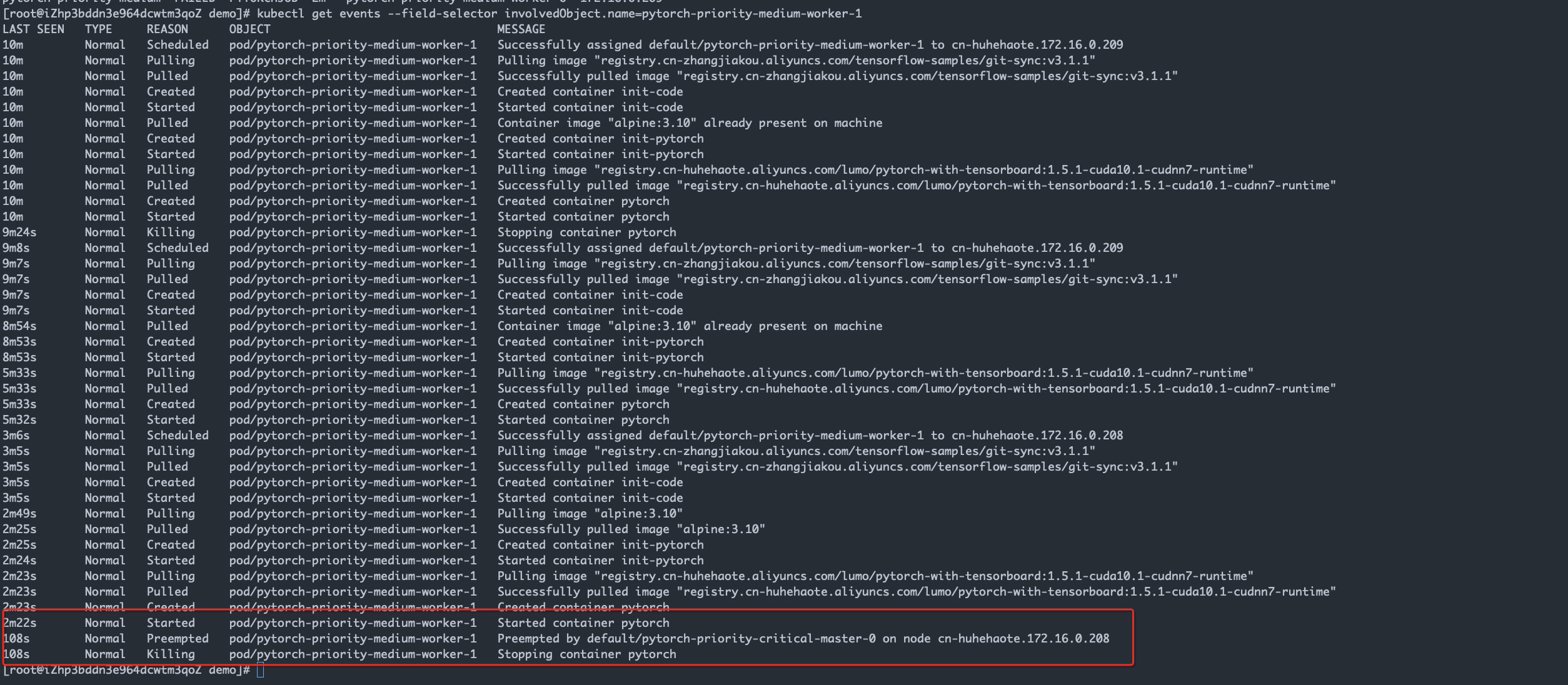
9. Check the event of the pytorch-priority-medium, and you can see that its python-priority-media-worker-1 has been expelled. The reason for the expulsion is that the python-priority-critical-master-0 is also applying for the resource of this node, and the node has no additional GPU resource, so the low priority job is preempted by the high priority job.
➜ kubectl get events --field-selector involvedObject.name=pytorch-priority-medium-worker-1